Traditional IT infrastructure monitoring focuses on hypervisor hosts, storage and VMs. Application impact is tracked through vSphere resource tagging. This simple and mostly static drilldown approach to full-stack monitoring no longer works for modern microservices based computing.
A New Set of Requirements for Monitoring Container Infrastructure
Short lifespan of containers: If used to host microservices, containers are constantly provisioned and decommissioned based on demand at a specific point in time. This can lead to cycles, where in the morning, a container host cluster is filled up with microservices belonging to Workload A, while in the afternoon, this same host is serving Application B. This means that the business impact of a security breach, slow performance or downtime on a certain host will have a very different business impact, depending on when it happens.
 The
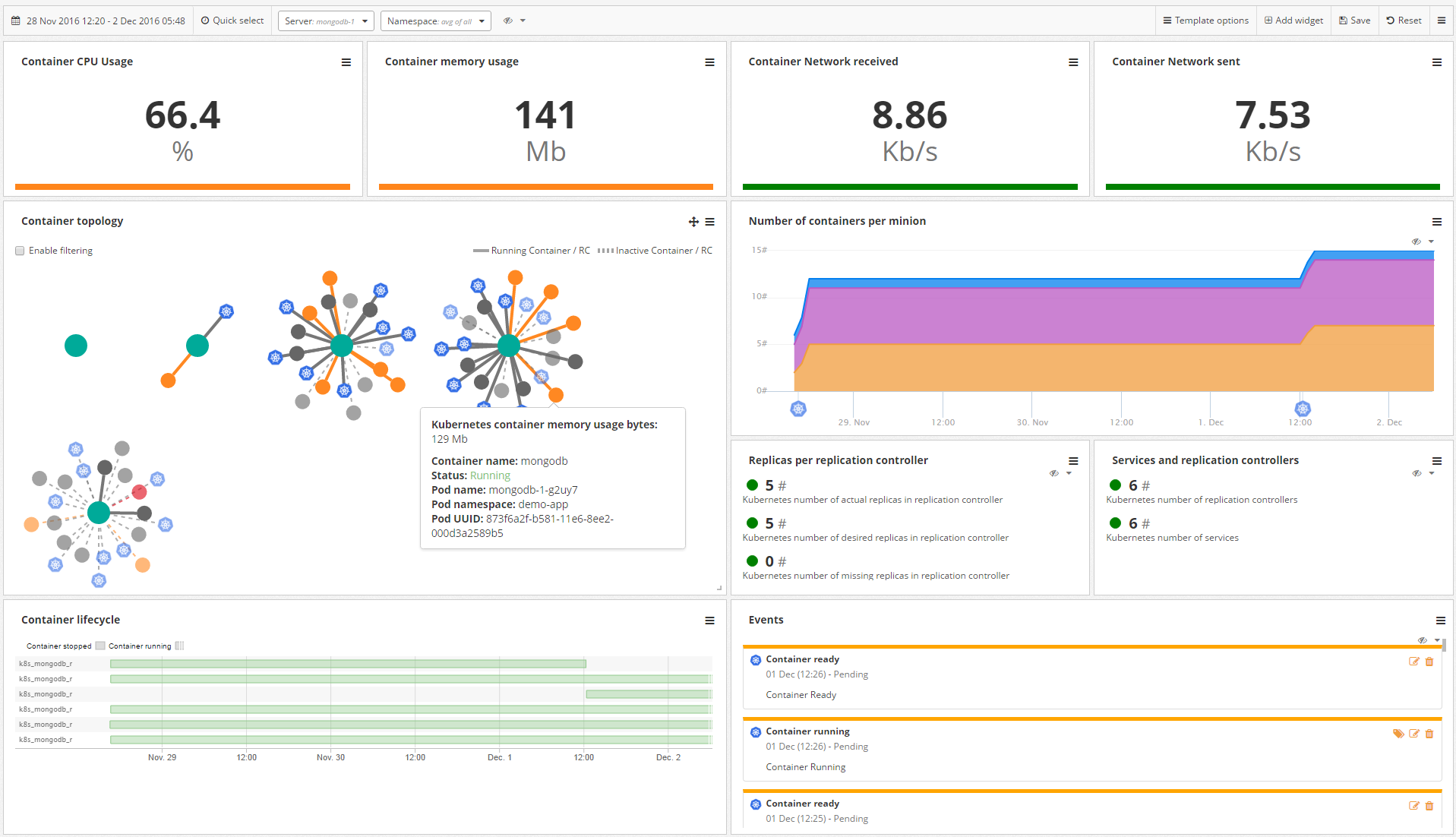
Coscale Container Monitoring Dashboard Shows the Topology of Containers, PODs and Namespaces
The
Coscale Container Monitoring Dashboard Shows the Topology of Containers, PODs and Namespaces
One microservice can be leveraged by numerous applications: As different applications often share the same microservices, monitoring tools must be able to dynamically tell which instance of a microservice impacts what application.
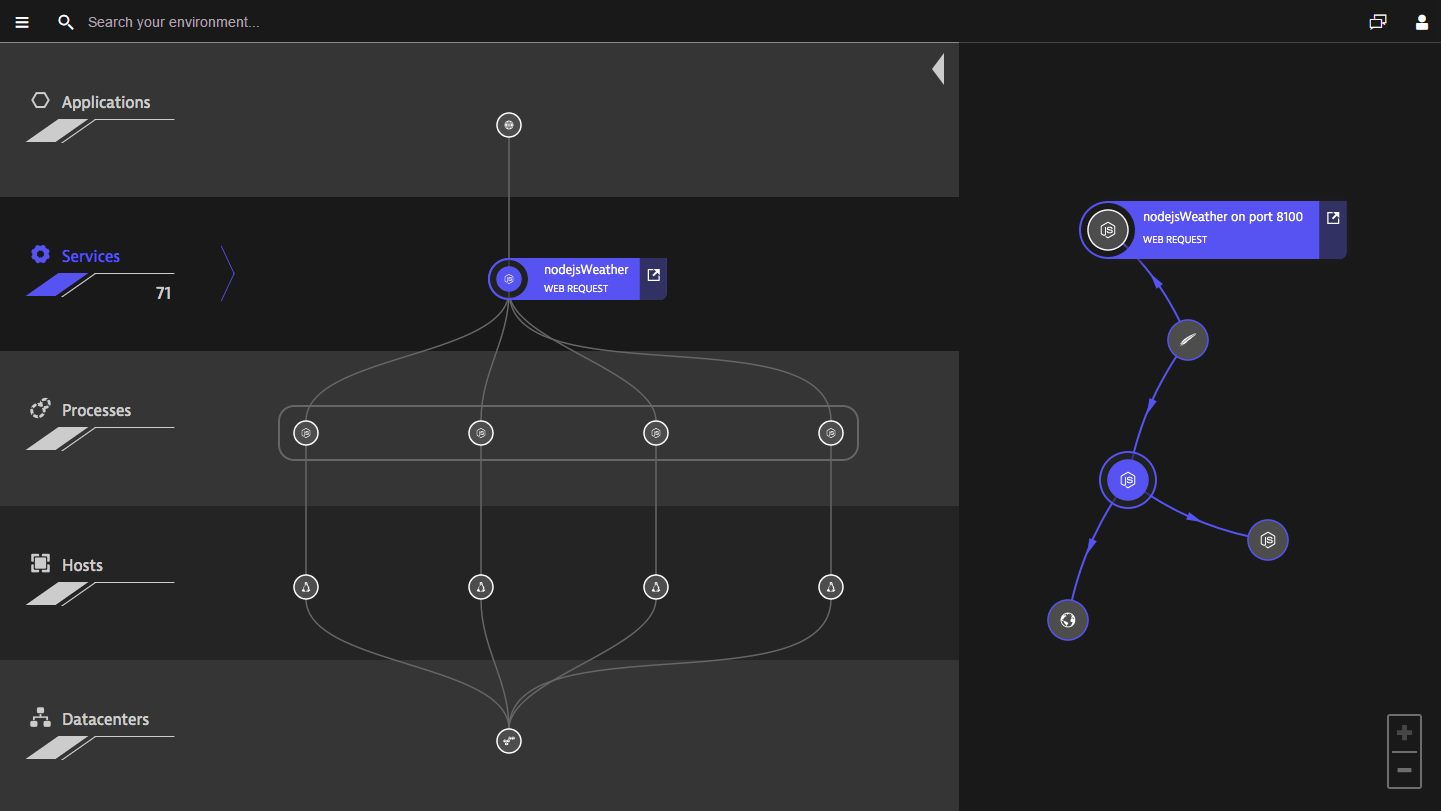 Dynatrace Keeps Track of Application Dependencies on Different Levels
Dynatrace Keeps Track of Application Dependencies on Different Levels
Temporary nature of containers: When the assembly of a new container is triggered based on a container image, networking connections, storage resources and integration with other required corporate services have to be instantly provided. This dynamic provisioning can impact the performance related and unrelated infrastructure components.
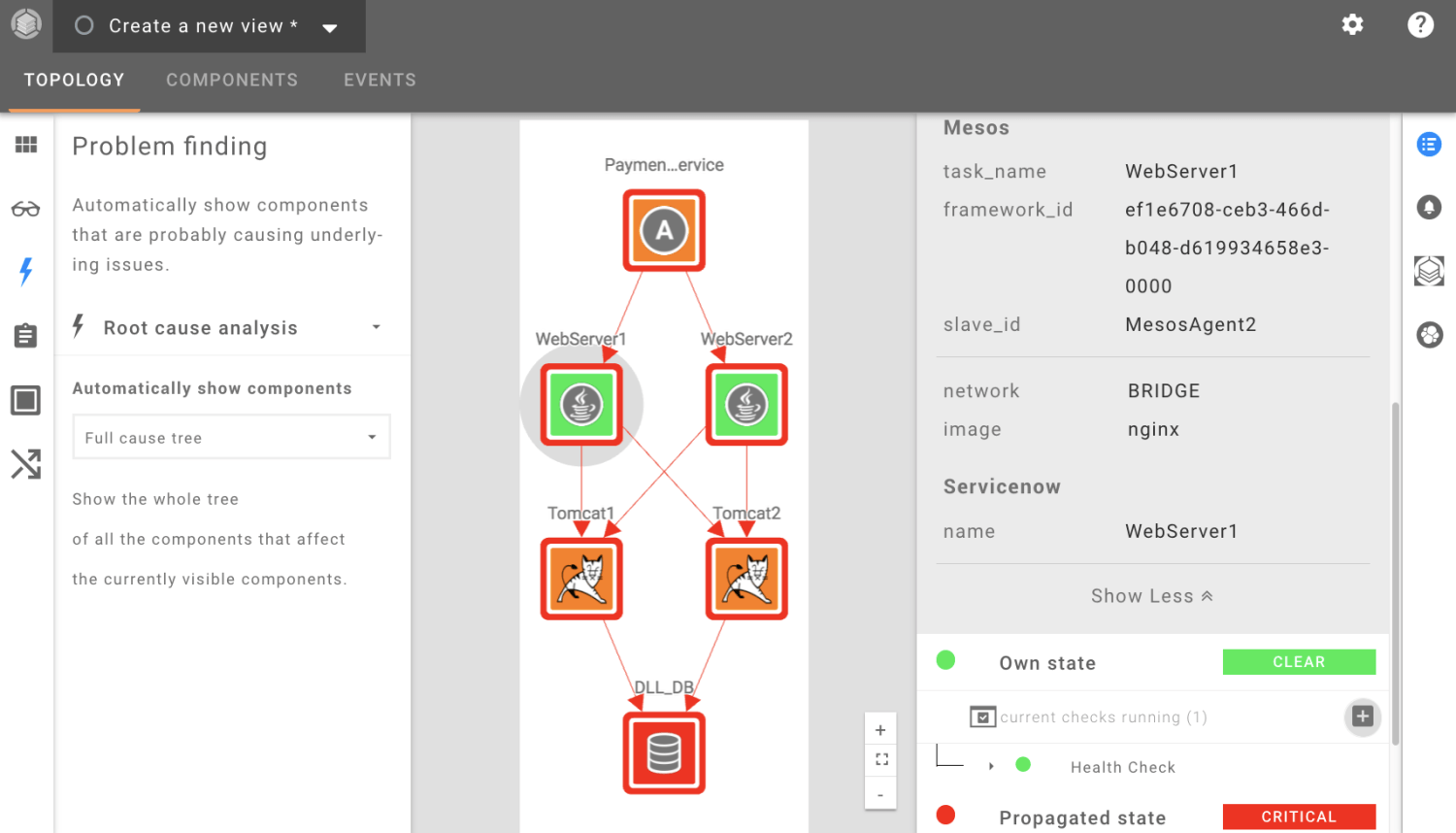 StackState offers Root Cause Analysis based on Topology, Components and Event Correlation
StackState offers Root Cause Analysis based on Topology, Components and Event Correlation
More levels to watch: In case of Kubernetes, enterprise IT needs to monitor at the level of Nodes (host servers), PODs (host clusters) and individual containers. In addition, monitoring has to happen on the VM and storage level, as well as on the microservices level.
Different container management frameworks: Amazon EC2 Container Services run on Amazon’s homemade management platform, while Google naturally supports Kubernetes (so does VMware), and Docker supports Swarm. Container monitoring solutions need to be aware of the differences between these container management platforms.
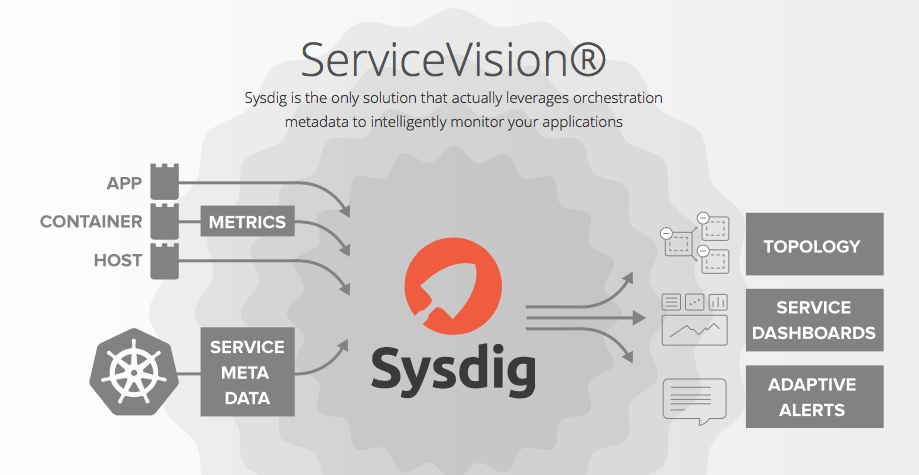 Sysdig Provides Full Stack-aware Metrics
Sysdig Provides Full Stack-aware Metrics
Microservices change fast and often: Anomaly detection for microservices-based applications is much more difficult than for standard apps, as apps consisting of microservices are in constant change. New microservices are added to the app and existing ones are updated in a very quick sequence, leading to different infrastructure usage patterns. The Monitoring tool needs to be able to differentiate between “normal” usage patterns caused by intentional changes and actual “anomalies” that have to be addressed.
Serverless Computing Needs Monitoring too
Organizations leveraging AWS Lambda, IBM OpenWhisk or Microsoft Functions will benefit from not having to worry about infrastructure scalability, paying for unused resources or operations management in general. However, serverless functions still need monitoring in terms of code execution failures, error handling, time to complete, resource consumption, number of requests, execution location, cost and so on. As serverless functions are often used as an extension to containerized or even standard applications, monitoring needs to happen within the overall application context. As an additional wrinkle, Lambda, OpenWhisk and Microsoft Functions are only a few examples of serverless frameworks and they do not adhere to a common standard, making monitoring more tricky.
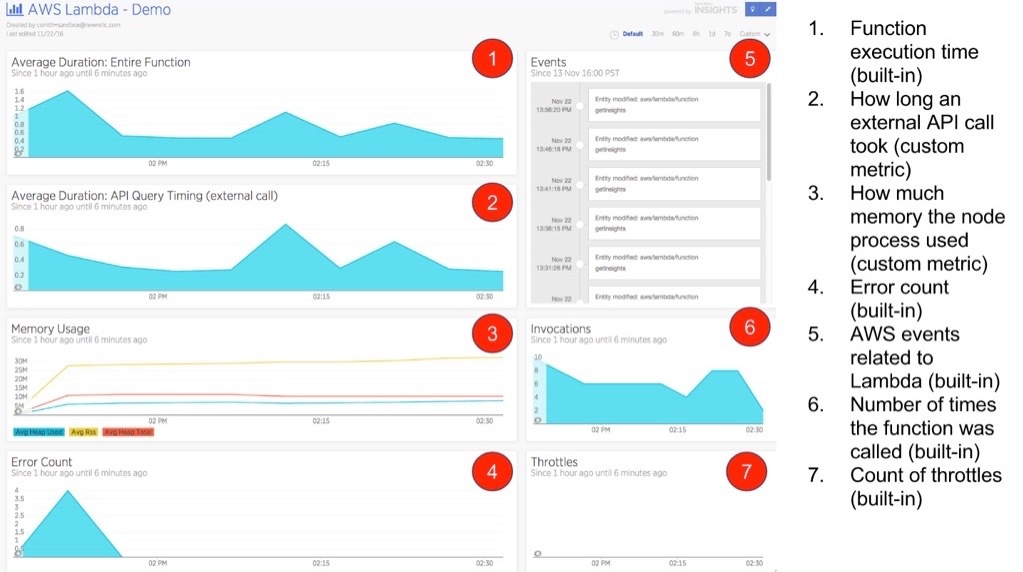 New Relic Lambda Monitoring Dashboard (source: New Relic)
New Relic Lambda Monitoring Dashboard (source: New Relic)
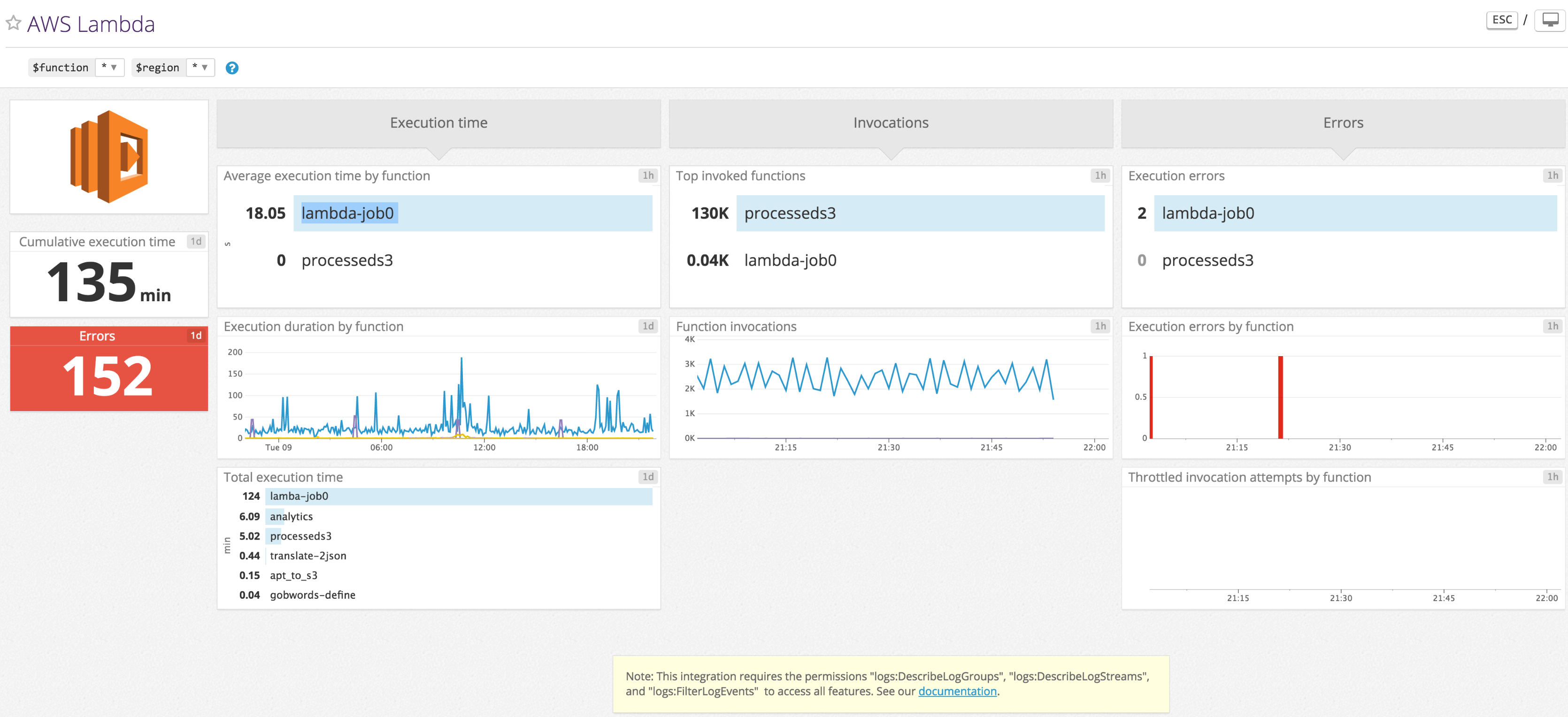 Datadog offers a full dashboard for AWS Lambda functions (source: Datadog)
Datadog offers a full dashboard for AWS Lambda functions (source: Datadog)