When we think back to why everyone’s favorite child named OpenStack failed so miserably to catch on in all but the largest enterprises, the conversation comes back to one central topic: OPEX. This topic consists of multiple dimensions:
Initial deployment and configuration: Integrating OpenStack within a traditional data center setting has shown very costly, as much custom integration work has to be done.
Separate set of management tools: New tools are needed to manage and monitor OpenStack environments. Especially performance and user experience management have proven to be difficult and costly.
Lack of hardware supporting scale out: Turn-key scale out of OpenStack environments has remained a myth, as the integration between server, network and storage infrastructure still is lacking. This leads to the necessity of manual workarounds, which often negates the benefits of a scale-out cloud.
Upgrades: While there has been significant progress in terms of how customers can upgrade their OpenStack environments, the upgrade topic is still far from resolved. E.g. what happens when the underlying hardware is upgraded or entirely refreshed? How will the apps respond to adding capacity?
In summary, scale-out clouds have traditionally been their own animal, focusing on running modern “born in the cloud workloads.” Maintaining this parallel universe of cattle alongside our traditional data center pets has proven difficult, resulting in the failure of many cool startups, such as Piston Cloud, Nebula, MetaCloud (now part of Cisco), HPE‘s Helion and IBM’s SmartCloud Orchestrator.
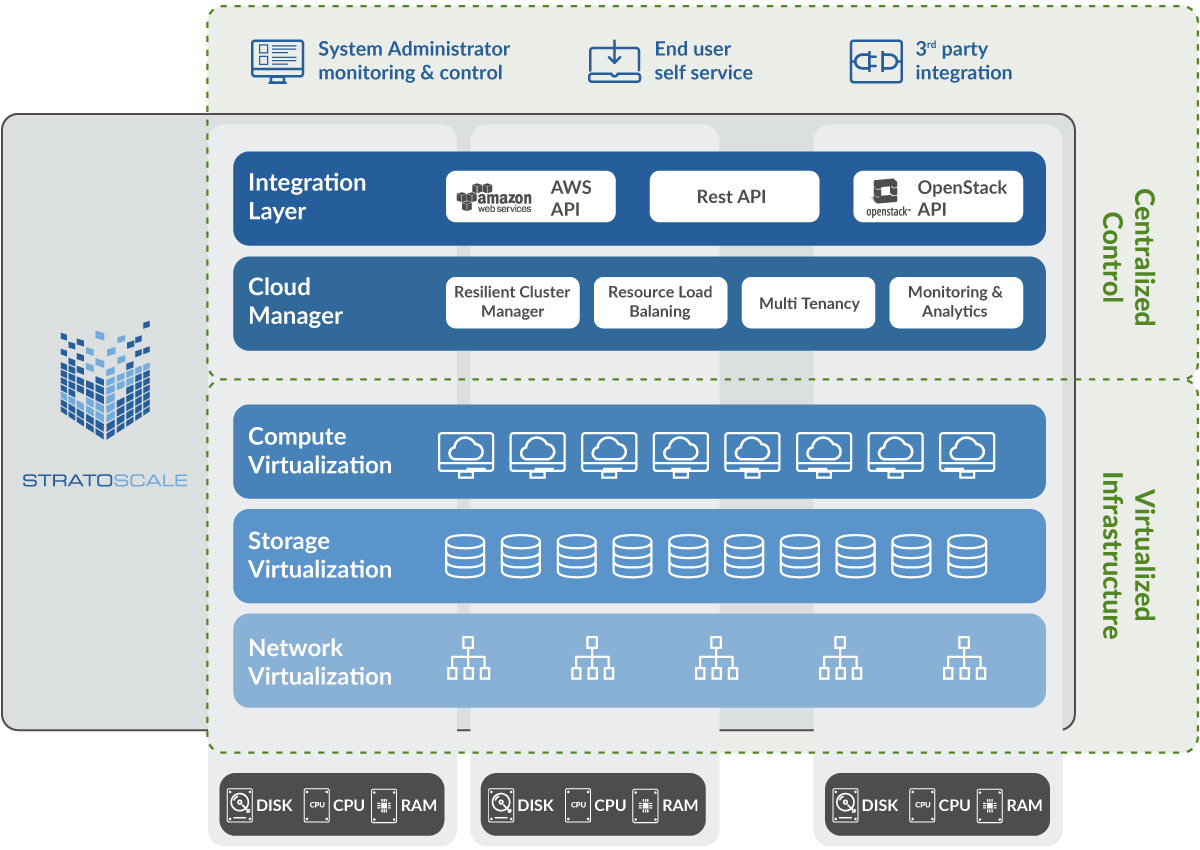
Cisco’s Cluster-Level Management is a Big Deal
Cisco’s year-old HyperFlex converged infrastructure systems show how much the company has learned form the failure of the first wave of scale-out clouds. In short, Cisco aims to offer the “holy grail” of cloud computing, where enterprise workloads and modern microservices-based apps can run side by side, in peace and harmony. Pets and cattle happily living together in the corporate data center means that enterprises can finally get their scale-out related OPEX challenges under control, as hardware infrastructure, automation and orchestration tools and cloud platforms can now be managed, monitored and upgraded using a common set of tools.
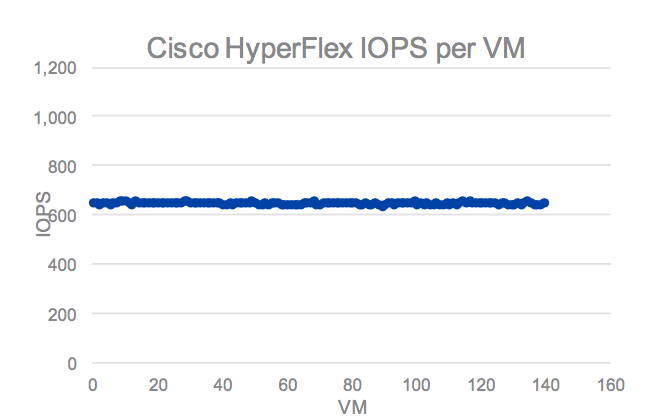
Consistent scale out performance (Source: Cisco)
And then of course, there’s Cisco’s secret sauce that makes all this possible. Their custom developed HX file system combined with the Cisco data fabric provide the network and storage performance needed to manage resources at the hypervisor cluster level, without having to worry about inconsistent VM performance. This allows customers to simply add more CPU (by adding UCS compute only nodes) and storage separately, as needed.
For a deep dive analysis of Cisco’s new HyperFlex 2.5, please take a look at our EMA Impact Brief on this topic (coming later today).