

As the race to deliver the UAW heats up, EMA sees the following vendors working toward a convergence of the data warehouse and data lake: Ahana, Amazon, Cloudera, Databricks, Dremio, Google, HPE Ezmeral, Incorta, isima.io, Oracle, SAP, Starburst, Teradata, and Vertica. EMA also anticipates that vendors that successfully deliver a unified analytics warehouse will quickly eclipse data warehouse and data lake vendors, making them obsolete, except for targeted use cases and analytical projects.
Developing an Information Management Strategy Within the EMA Hybrid Data Ecosystem
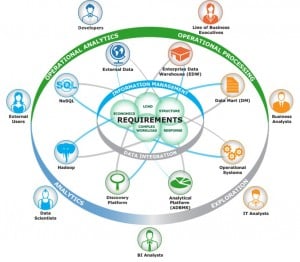
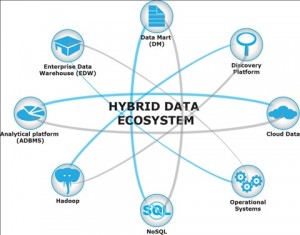
Enterprise Management Associates (EMA) has recognized that big data implementers and consumers rely on a variety of platforms to meet their big data requirements. These platforms include new data management technologies such as Hadoop, MongoDB, and Cassandra, but the collection also includes traditional SQL-based data management technologies supporting data warehouses and data marts; operational support systems such as customer relationship management (CRM) and enterprise resource planning (ERP); and cloud-based platforms. EMA refers to this collection of platforms as the Hybrid Data Ecosystem (HDE):
Topics:
Data management
Apache Hadoop
HBase
SQL
Big data
Business Intelligence
Hortonworks
MongoDB
NoSQL
ODBC
Cloudera
John Myers
Continue Reading
Return on Investment (ROI) of Data Science as a Service
In skiing, the “black diamond” run or ski slope is often referred to as “high risk/high reward.” You receive lots of “reward” skiing the black diamond slopes, but you have a significant amount of “risk” associated with variable terrain, such as the presence of trees and the possibility of injury. However, the black diamond slopes are very fun to experience, and you can mitigate the risks with preparation, practice, and a really good skiing helmet.
Topics:
Apache Hadoop
cloud computing
Big data
Business Intelligence
Data science
Hadoop
MapReduce
Data analysis
Data warehouse
John Myers
Continue Reading
EMA Research: Enabling Enterprise IT Management to Optimally Support Big Data

What does Big Data mean to traditional enterprise IT? Organizations of any size and industry are becoming more and more aware of the incredible importance of capturing, managing and analyzing the data available to them. The more comprehensively companies are able to tap structured and unstructured data sources, the quicker they can refresh this data and the more successfully they make this body of data available to all business units, the better they can develop advantages in the market place. Today’s business units are demanding the rapid implementation of these big data use cases, as well as optimal resiliency, cost efficiency, security and performance.
Topics:
cloud computing
Information technology
IT Management
Big data
Systems Management
Infrastructure
Systems management
Information technology operations
Enterprise IT Management
Torsten Volk
Unstructured data
Continue Reading
Data Management: In-Memory Could Be the Mother of All Wisdom
As I review my series of #100linesOnBIDW blogs over the last couple of weeks, I found myself looking at the Data Management posting. I covered when to apply schemas, Big Data, and data governance. What I left out was technical implementation concepts for data management systems like row vs. column orientation; in-memory vs. spinning disk primary storage; and symmetric multiprocessing (SMP) vs. massively parallel processing (MPP). Processing and storage were the “developments” of 2012. I left 2013 for the “how to use” Data Management platforms.
Topics:
Data management
Big data
Business Intelligence
Computer data storage
Hardware
In-memory database
Database management system
John Myers
Solid-state drive
SSD
Continue Reading
Data Management in 2013: Warning of the Big Data Wolf
When Aesop created the fable about the shepherd boy who cried wolf, the message was clear:
Topics:
Data management
Big data
Business Intelligence
Facebook
Harvard Business Review
Data governance
Data model
John Myers
Continue Reading
Data Integration in 2013: Give us a platform and we will fill it
“Back in the day”, Pablo Picaso once said:
Topics:
Big data
Business Intelligence
Data integration
Extract transform load
Hadoop
Data virtualization
John Myers
Continue Reading
What Big Data Is Not
Next week, EMA and 9sight will hold a webinar covering our Big Data research findings. Among our insights will be that Big Data has evolved. Moving forward, Big Data isn’t:
Topics:
Data Mining
Apache Hadoop
Big data
Business Intelligence
Databases
EMA
Barry Devlin
Data Warehousing
John Myers
Technology
Continue Reading
Is there a NoSQL Identity Crisis
As Big Data initiatives mature into enterprise data sources supported by NoSQL products for analytics and operational systems, a clash of cultures is on the horizon (if not here already). Traditional IT implementations teams and their top-down programs rarely see eye to eye with the grass roots culture of NoSQL platform operators. But this divide is not merely between the camps of Big Data/NoSQL and traditional IT implementation teams. This is just the tip of the iceberg…. The divide becomes much more pronounced when you take the discussion to the executive suite. CMOs and CFOs, who “own” results of analytical and operational systems, are less concerned with data center standards and development methodologies as they time to value. CIOs and CTOs, responsible for implementing the connectivity and integration between NoSQL platforms and the rest of the traditional IT environment, are facing pressures to avoid chasing the latest technology fad(s).
Corporate Data Return on Investment
Informatica Goal: Maximize Return on Data
The theme of last week’s Informatica Analyst Conference was utilizing the “secular megatrends” of information technology to energize data integration across organizations at an enterprise scale. These megatrends, described as trends we can all agree upon, are the following:
Topics:
cloud computing
Big data
Business Intelligence
Data integration
Hadoop
Informatica
John Myers
Continue Reading
