The ability to execute in a low latency time frame is a core component of the concept of next generation data management architectures such as the Enterprise Management Associates Hybrid Data Ecosystem (HDE). One of the key business drivers of the HDE is speed of response, which stems from an organization’s drive to execute faster than their competitors to create an advantage or to be on par with those competitors to simply “keep up with the Joneses.” You see this in workloads such as cross-sell/up-sell opportunities for revenue generation. You see this in opportunities to limit costs with asset logistics and labor scheduling optimization. You see this in opportunities to limit exposure to risk in fraud management and liquidity risk assessment.
There are many platforms in the HDE that support low latency processing to fulfill operational analytical workloads. Columnar-based analytical databases/appliances provide low latency processing. The Spark subproject of Apache Hadoop provides the speed of response that many organizations are looking for to establish or maintain competitive advantage.
However, it is the data management platforms that implement in-memory attributes as part of their SQL-based architectures that may provide the best low-latency processing to provide the near-real time processing that organizations are looking for in business contexts. Examples of in-memory platforms include SAP HANA, Kognitio Analytical Platform, Oracle TimesTen, IBM DB2 with BLU Acceleration, and Pivotal (nee, Greenplum) GemFire.
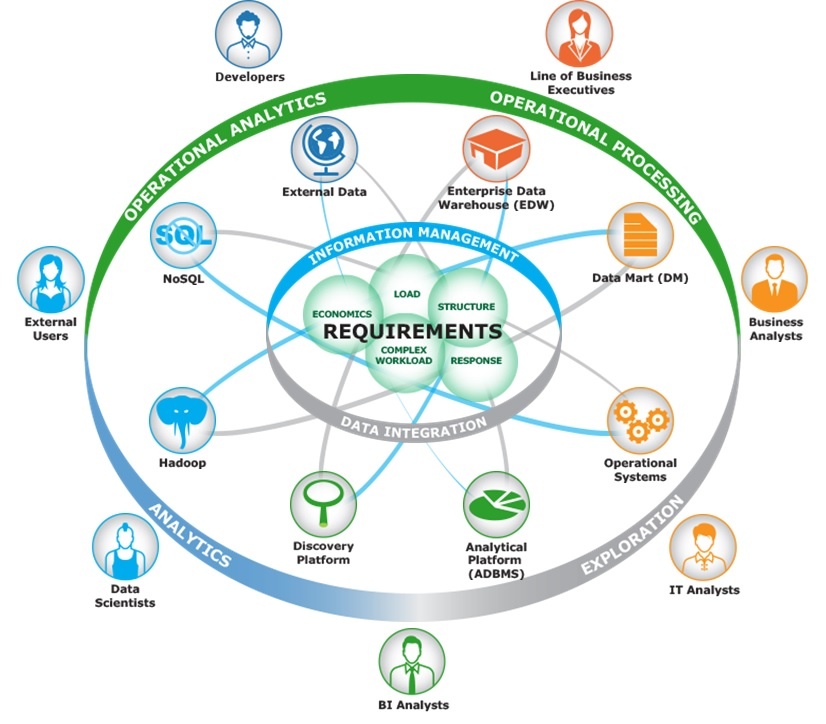
However, management of the distribution of information from other parts of the HDE to those low-latency in-memory platforms requires coordination for several reasons. The first reason is that the low-latency, in-memory platforms mentioned above often are not designed for the mass ingestion of data that is associated with big data environments or large amounts of transactional event data from operational support systems (OSS). This information often resides in the OSS systems or a NoSQL platform such as Hadoop. Next, the information that provides the context for the operational analytical workloads associated with customers, products, and regions is often located within an enterprise data warehouse (EDW). The requirement to bring these data sets together to provide the detail data and context for analytical workloads such as fraud management and cross-sell/up-sell is positioned within the Hybrid Data Ecosystem’s Information Management Layer. The Information Management Layer makes it possible to have multiple points of data management and storage coordinating the access and location of that information across platforms to meet the low-latency business requirements of speed of response.
The ability to manage these particular data needs while optimizing the information stored on an in-memory platform is a key component of the HDE’s Information Management Layer. Software tools that can provide the ability to selectively migrate information to these in-memory platforms allow organizations to build the analytical models that operational analytical workloads depend upon. Building these models often requires an organization to model new information, test the results, and evaluate those results before the model can be fully implemented in a production setting. Call these locations skunkworks for prototypes, discovery sandboxes, or development environments, the requirement is still the same. These environments require a limited set of “real” information to build accurate models.
When these models move into production, the HDE’s Information Layer requires that full versions of the exact information that meets the requirements of an operational analytical workload be made available to the in-memory platform. This ensures that only the information that correlates to the model is migrated and maintained. Whether the data is provided via a virtualized service or as a replication process, it is key to the accuracy of the operational analytical workloads to provide the information accurately in terms of both the information provided and freshness of the data to make sure that cross-sell/up-sell offers are made with the correct purchasing history and that fraud management decisions are made with the best (i.e., highest correlation) variables.
For organizations implementing operational analytical workloads within an SAP environment, SAP HANA is a preferred in-memory data management and processing option. SAP business applications provide the event and contextual information necessary for operational analytical workloads, and SAP HANA is a strong low-latency processing platform that meets the speed of response requirement. However, to be effective, this architecture requires an in-depth knowledge of SAP data locations and data integrity constraints. A product such as Attunity Gold Client Solutions empowers organizations to navigate SAP application structures to identify and migrate the correct information to develop operational analytical models, whether the data is at a detail level or at a contextual level. Gold Client Solutions also provides the type of data access necessary on an ongoing basis to feed the production version of those models with the information necessary to maintain competitive advantage.