
The race for a unified analytics warehouse is on. The data warehouse has been around for almost three decades. Shortly after big data platforms were introduced in the late 2000s, there was talk that the data warehouse was dead—but it never went away. When big data platform vendors realized that the data warehouse was here to stay, they started building databases on top of their file system and conceptualizing a data lake that would replace the data warehouse. It never did.
Data lake platforms quickly demonstrated the value of semi-structured data. As data lakes grew in popularity, data warehouse vendors saw them encroaching on their territory, so they began to shift their databases to run on file systems and started finding ways to process semi-structured data.
Within a few years, nearly every organization that ran a data warehouse also stood up a data lake. The two existed side by side. Initially, there was some data sharing between the two platforms, but not much more. Pressured by customer demands to run analytics across both the data lake and the data warehouse, vendors on both sides began working toward a more complete integration of a warehouse and lake. The race began.
The Reason for the Race
Digital, mobile, and the Internet of Things (IoT) changed the way modern companies operated. Digital transformation proved that semi-structured data is as important as transactional, structured data. Both need to be analyzed to create a competitive advantage. Unfortunately, neither the data lake nor the data warehouse was adequate to handle the analysis of both data types.
The data warehouse was inadequate because it was built for structured data and required structuring and ingestion of semi-structured data to analyze it. The data lake was inadequate because the associated database technology lacked enterprise capabilities and did not perform well. Analyzing each type of data separately was not the answer. Only structured and semi-structured data combined could deliver on the promise of complete business insights.
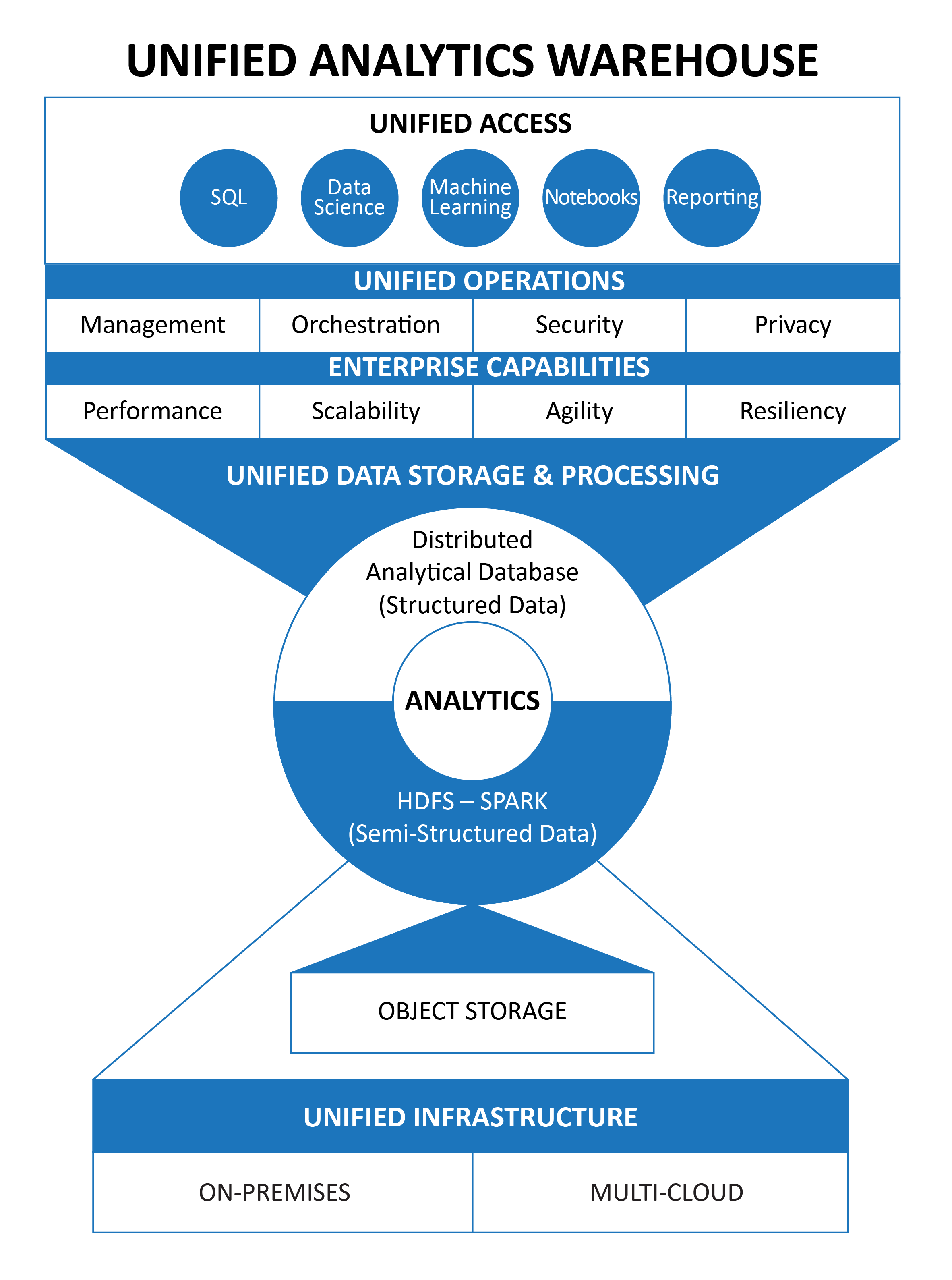
The Unified Analytics Warehouse
Driven by customer requirements, both camps have been consistently pushing toward a unified analytics warehouse (UAW). It is unified because it adequately handles multi-structured data in a single platform. It is an analytics platform because the primary use case for both the data lake and the data warehouse has always been analytics. The data lake has focused more on data science use cases and the data warehouse has focused more on enterprise analytics. It is a warehouse because it stores multi-structured data in an organized and accessible manner.
From the data lake side of the race, nascent data platform vendors who built their data architectures to handle semi-structured data are working to build database technology, including structured columnar storage formats and SQL query engines, on top of their file-based data storage systems. Because the data is typically stored in a file system, providing access to object storage, like Amazon S3, was either built-in or easy to build. Data lake technology was built for structure-on-read processing, making it readily accessible to the typical discovery analytical work done by data scientists. Vendors on the data lake side are working to make complex analytical processing more readily accessible and performant on their platforms.
From the data warehouse side of the race, mature database vendors built for structured data are working to access both semi-structured data and tiered storage. Columnar MPP databases were built for high-speed analytical processing, and some databases have worked to provide notebook and data science access to their platforms. In addition, it is becoming more common to see machine learning algorithms embedded in data warehouse technology for high-performance processing of advanced analytics on structured data.
Hurdles to Overcome
The convergence of the data lake and the data warehouse is not without challenges from both sides of the race. On the data lake side, it is extremely difficult to build an enterprise-ready database. History dictates that it takes at least ten years to harden database technology and make it safe and reliable enough for enterprise customers. Many data lake vendors currently tout the release of some enterprise database features, but most are a long way off from the deployment of full enterprise-strength database functionality.
On the data warehouse side, it is challenging to break out of the structure built into a database and to open the technology for semi-structured data and random discovery of analytical workloads. In addition, it is difficult to loosen the tight storage to compute coupling to work with tiered storage. Leaders among the analytical database vendors are already finding ways to overcome these challenges. EMA believes they will be the winners in the race because of the amount of time it takes for data lake vendors to build a proven and reliable database.
For the rest of the story, read the full white paper, The Emergence of the Unified Analytics Warehouse – Data Lakes and Data Warehouses Merge.



