
Neural Networks Are Key in 2018
Neural networks are back, but please don’t think they are able to emulate the context awareness of the human brain. Don’t get me wrong, I believe that the neural network approach is a viable one, but we do need to be clear about its limitations. All of these limitations are rooted in the limited 'worldview' the neural network is able to take in. This worldview is limited as it relies on a human being with limited time and knowledge creating the neural network topology by providing the following components and enough sample data for the machine to determine how input should be processed.
How Neural Networks Turn Input Parameters into Output Values - Discussing Some Inherent Limitations
Basic Principle: The Input Layer receives a predefined number of situational parameters that are then processed in one or more hidden layers. This then results in one or more output values.
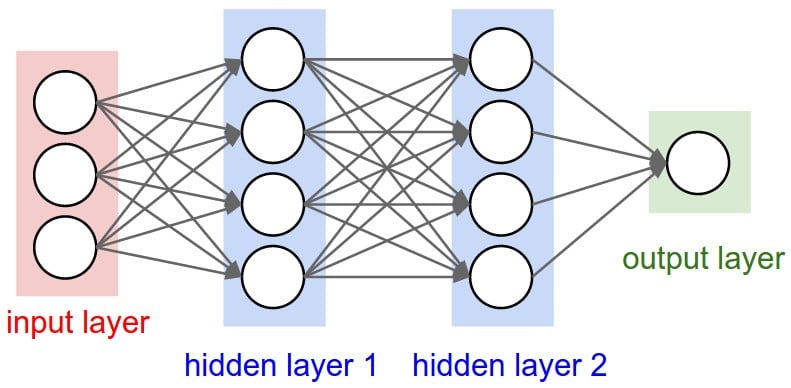 Basic Neural Network Structure. Credit: PyImageSearch
Basic Neural Network Structure. Credit: PyImageSearch
Training Steps:
- Provide sample input and output: Feed in sample data and manually providing the correct output values.
- Based on the sample inputs, the machine calculates the value for each node, compares the output values to the training data, and shows the error term for all neurons on the hidden layers.
- The machine adjusts each node's value based on the error term and calculates output values and new error terms.
- Repeat until results are satisfactory.
Key Components of a Neural Network
Input Layer: Defines which values are relevant for an optimal result. This is a key limitation as...
- ...the data scientist may not have sufficient domain knowledge to identify all relevant input factors
- ...for more complex problems there may be hundreds or thousands of input factors required
- ...humans have the ability to dynamically include or exclude situational input factors based on temporary priorities
- ...input factors can change based on tactical or strategic changes, based on new scientific discoveries, new laws, etc.
Hidden layers: The more complex the relationship between input and output variable, the more hidden layers are needed. However, this rough guidance leaves many questions unanswered:
- How many hidden layers to I need for a specific problem? How many neurons should each layer have?
- How much additional accuracy and resolution do I get when I add more layers?
- How does the availability of training material influence the number of required hidden layers?
- What's the impact of a specific learning algorithm on the number of required hidden layers?
- How do I prevent hidden layers from 'getting stuck' and negatively influencing other layers?
Algorithms:
- How to optimally fit them to a specific neural network topology?
- How to select algorithms to enable broader results?
Output Layer
- How do I select a realistic set of output variables?
- How many outputs make sense?
Limitations of Neural Networks and Requirements for 2018
We do not understand how neural networks reason, as we cannot look under the cover to see how it makes decisions. Humans only know the model topology, including the dimensions and depths of the neural network. What they don’t know is how the network learns and how it arrives at its decisions. This leads to trust issues leading human operators to constantly question and overwrite machine decisions, even though they are likely superior to human reasoning. I could name a list of machine learning vendors that didn’t make it due to their inability to convince human operators to trust them and on the other side enterprises waste thousands of hours by over training machines, just to be sure all bases are covered.
Questions the machine has no answer for: Is your decision based on concrete empirical evidence? Has this same decision worked out in a similar situation in the past? How likely is it that the decision will lead to disaster? Show me the key reasons for making this decision?
No Feedback on Cause and Effect
The machine does not receive clear feedback of whether or not its decision was successful. This lack of unambiguous feedback is one of the key long term challenges preventing the success of machine learning, as in complex situations there may be many interfering variables not observed by the system and the impact of the output variable may only be observable in the undetermined future.
Example: The machine makes a decision in terms of how to configure a specific database server and the resulting server seems to work just fine. However, 6 months later the entire database cluster goes down due to a potential interaction between the initial configuration and a database plugin that was installed later. What should the machine learn from this episode? Maybe all the fault was on the side of the new plugin? Maybe there was an interaction between that plugin and a Windows patch or maybe between the Windows patch and the initial db configuration done by the machine? This is just one of hundreds of examples that come to mind where the cause and effect between input and output is unclear.
AI needs to show its key decision factors within context
In order for humans to trust machine decisions, they need to see 'how the sausage was made.' Especially in complex situations as described under my 'cause and effect' example, humans can only start trusting machine decisions that are transparent.
Example 1: When the machine says, move a container host from Amazon ECS to Azure Container Service, I will need to know why it believes that the migration is worth the cost and risk and what is likely to happen if I do nothing.
Example 2: When the machine says, ‘you need to change the following Tomcat parameters,’ I will want to know what type of issue it expects if I leave the current configuration in place and why. I want to also know the key indicators that led to this warning. The latter is challenging, as these indicators are defined without any pre-labelling, meaning that the machine will have to come up with its own definitions that are understandable by us humans.
AI needs to learn how to create labels WITHOUT training
If it walks like a duck and talks like a duck, but it is too large for a duck and it can’t swim, the machine should be able to use a dictionary to look up ‘birds, that have the same beak, neck, wings, and feathers as a duck, but are about 20% larger than the largest known duck and are unable to swim.’ If this is still too ambivalent, the machine should then be able to look at the background of the photo and try to determine where it was taken. It can then further narrow down the list of probable birds and output the least of features that led to the final classification decision. It could then tell me which other birds it ruled out and why.
Neural networks need a probabilistic component to learn by examples
This is what I was asking for when half-jokingly demanding that the new VMware vSphere version should have an AI admin built-in. A probabilistic model would watch the admins basic behavioral patterns and derive a) best practices and b) issue remediation procedures from these patterns.
Example: The admin always follows a specific set of steps when creating a new storage volume and adding it to a pool for self service via vRealize Automation. From this the machine can learn, with a high probability, how that same admin would go about creating a new storage volume for disaster recover, for staging, and for most other purposes. So the machine goes and starts provisioning volumes exactly that same way until it notices that the human admin now repeatedly follows a slightly revised process for provisioning volumes for software developers only. This tells the machine a) that software developers are treated differently, b) that they are treated differently when it comes to storage, c) that they are a meaningful entity, d) that sometimes storage can be provisioned differently for different groups. These learnings now influence the machine’s worldview when it comes to other areas. For example, it could deduce that ‘if developers receive differently configured storage, it is OK to also configure their compute components differently compared to the other groups.’
To be continued...



