Now that I’ve predicted that in 2018 machine learning will be available to ‘average Joe developer,’ let me share my experience from this weekend. Note that I’m not trying to be a ‘cool geek’ by doing some hands on work (I’m way too old to still be cool), but based on all the machine learning and artificial intelligence buzz in 2017, I thought my use case should be quick, simple, and most importantly solving a problem that could otherwise not be solved.
Building My Water Monitoring Dashboard - And No, Fish Don’t Practice their Backstroke
I’m currently building a ‘nature aquarium,’ where everything is about the illusion of replicating an untouched piece of stream, river, or lake. Of course, this illusion requires some high tech in the backend, with numerous sensors, monitoring devices, and other tech to measure, report and, ideally, auto remediate water parameters. Undetected water issues can quickly lead to your kids walking down the stairs to say good morning to their fish and then ask something like “Daddy, why are our fish all swimming on their backs? Are they practicing for the Olympics or something?”
The Tech Challenge - It's Kind of Simple
Now the problem is that all the high quality monitoring devices only offer unreliable and very expensive wireless communication interfaces, so that you are left with a good chance of paying the high price tag, just to be cut off from the system when you are on the road and of course who knows if the auto remediation capabilities will work or also fail.
This challenge was perfect for a quick machine learning-driven project where I use a standard IP camera or a spare smartphone to read the various 7 segment LED displays of my semi-professional lab equipment and log the data to a Google doc and use IFTTT for auto remediation. Sounds simple, right?
Why Machine Learning Is Critical
The aquarium technology cabinet is a dynamic system with displays and gauges being moved, added and replaced. I want to be able to capture them all with a single camera and I do not want to have to revise my software or worry about failure when I add another monitoring device. So here is what I expected the technology should do for me:
- Analyze a camera snapshot and identify where 7 segment display are located.
- If I add another 7 segment display, the solution needs to identify this automatically.
- If the displays goes darker, brighter or if the color changes, the data logging needs to continue.
- If the displays move the software needs to track this.
- Output: JSON with all the relevant data that can then be written to a Google Sheet. I did not expect any content tags, such as PH, temp, TCD, etc. as I can write a few lines of code to deduce this myself based on the number ranges.
The Sobering Prototype - Even Simple Machine Learning Is Not Turnkey
Please note that while I’m only describing this one specific project, the experience I’m basing my closing comments on is much larger and based on hands-on experience over the past decade and a half.
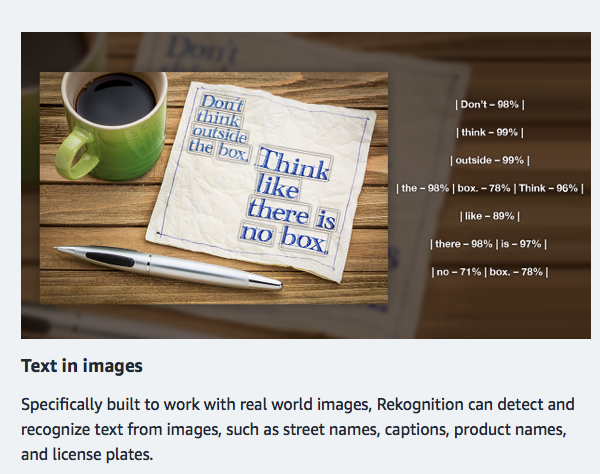 AWS uses a sample for their Rekognition on their website that is very similar to my use case
AWS uses a sample for their Rekognition on their website that is very similar to my use case
All in all, results were spotty and unreliable, which is disappointing, as this is a simple use case and the capability to recognize text and numbers in images is advertised as an out of the box feature of AWS Rekognition and Azure Visual Recognition. I used the iPhone 7S Plus dual camera with optimal lighting and at its highest resolution. I repeated the same test with numerous different 7 segment displays from all types of devices and even downloaded high resolution images from Google Image Search to ensure there isn’t anything wrong with my own setup. My pictures look very similar to the samples provided on the AWS and Azure websites. I did not pre-process the image at all, but neither do AWS and Azure for their demo setups.
Let’s take a look at some samples
These samples show that we get good results in approximately one third of samples. In the remaining cases we saw two different phenomenons: the system did not recognize the area of the 7 segment display at all. This happened in over 50% of my test cases. Then if it recognized the 7 segment displays as such, there still was an almost 40% chance of the numbers being incomplete or wrong.
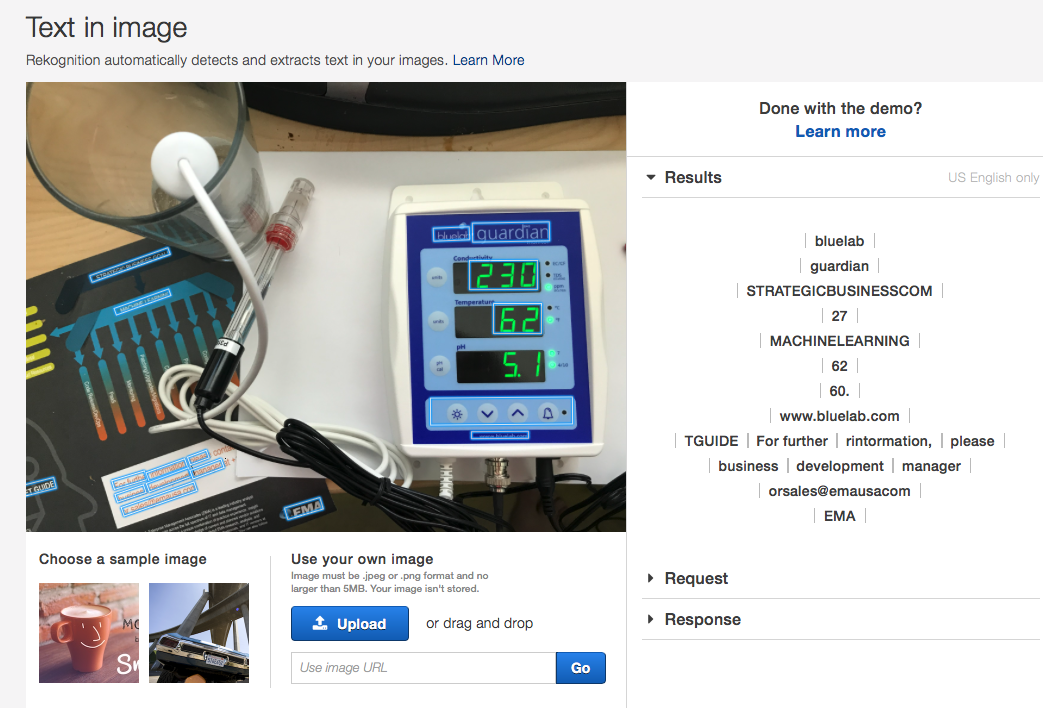 Both the 230 and the 62 were recognized as numbers. However, only the 62 was transcribed correctly. The 5.1 PH value at the bottom was not recognized as text or numbers at all.
Both the 230 and the 62 were recognized as numbers. However, only the 62 was transcribed correctly. The 5.1 PH value at the bottom was not recognized as text or numbers at all.
My Guess: AWS Rekognition and AWS Visual Recognition were not trained to recognize 7 segment displays. My guess is that if I invested the time to get them trained myself, I could get the result quality up significantly. However, I was looking for a turnkey solution and I definitely cannot invest hours to get the software trained only to then find that it still needs much more work or maybe it just cannot be done.
What Do We Learn from This? Where Do We Go from Here?
Key lesson here is that in 2018 we need to start applying machine learning to as many use cases as we can and report back all the little and major bumps in the road so that vendors can work out the kinks in their software. Also, vendors and peers need to see that us business users are hungry for more and better day to day machine-learning driven solutions. For example, if my aquarium solution had worked I would have gone and used Rekognition for other use cases right away and also recommended it to peers and colleagues. Once these tools become as easy and useful as they can be, the results will be life changing and adoption will be rapid. Whichever vendor figures this out first, will have a head start.